Social Sharing block
Many practitioners have been taught to describe a process using sigma levels. Yet these levels are commonly misinterpreted. This article will help you to understand the problem and learn more appropriate ways of describing your process.
|
ADVERTISEMENT |
In the days before handheld calculators and personal computers, students in SPC classes were taught to estimate the fraction of nonconforming product by converting each specification limit into a z-score and then looking up the fraction nonconforming using a standard normal distribution. Since the normal is the distribution of maximum entropy, this approach would, in most cases, yield worst-case estimates for the fraction nonconforming. Figure 1 shows these traditional fractions nonconforming for symmetric specifications spaced at different distances from the mean.
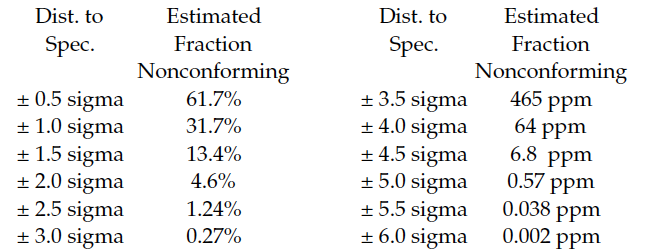
Figure 1: Traditional sigma levels
The first thing to note from Figure 1 is that the estimates are spread out over nine orders of magnitude. This will complicate the job of obtaining reliable estimates.
…
Comments
Thanks for this!
I tried submitting articles to a couple of other organizations a couple of years ago...I was politely told that no one really cares any more. However, some quality standards still claim that the 1.5-sigma shift is used "by convention." Don, maybe we should have been at that convention.
1.5 sigma was, in fact, a test value Michael Harry used for design parameters at Motorola. He would tell his engineers to shift inputs 1.5 sigma as a worst case when running simulations, as a means of checking for robustness in their designs. It was never conceived as a process metric, but someone with little knowledge but a lot of influence somehow got hold of it and decided it was just what the Six Sigma world needed.
Deming used to say "there is no substitute for knowledge." Clearly, someone with actual knowledge of variation would have headed this off at the pass, but that didn't happen. Anyone with a modicum understanding of variation and SPC would have realized that it was an impossible scenario, and that those "process sigma" charts are complete nonsense. Unfortunately, It proliferated due rule four of the funnel and a lot of novices teaching a lot of neophytes.
Harry initially based his 1…
Harry initially based his 1.5 sigma shift on the height of a stack of discs. Pure farce! I've attached the relevant extract from his "Resolving the Mysteries of Six Sigma" here: https://www.youtube.com/watch?v=0kZbJLHK_4M
Harry then concocted his "Chi Square proof" ... just as ridiculous as his stack of discs. It then became a "maximum move", then a "correction", then "not needed.
In short, the 1.5 sigma shift, that formed what Harry called "the pillar" of Six Sigma, was destructive fraud, built on farce.
https://www.qualitydigest.com/inside/quality-insider-column/six-sigma-psychology.html
1.5 sigma shift - the "pillar" of Six Sigma.
Don, you say "However, this claim is completely without foundation in either theory or practice." The "theory" was concocted by school teacher and self-confessed con man, Mikel Harry, in his "Resolving the Mysteries of Six Sigma". Harry said the 1.5 sigma shift was "the pillar" of Six Sigma.
Six Sigma started with uni drop-out, Mr Bill Smith and his out-of-control molding process that happened to drift “as much as 1.5 sigma” because of his tampering. Smith's parts shrank a claimed 15%. Harry “proved” Smith's disaster happened for every process in the world ... based on the height of a stack of discs!
Birth of a fraud:

https://QSkills3D.com/resources/birth.html
Add new comment