Social Sharing block
Over the past couple of articles, we have explored how an incomplete understanding of how SPC limits are calculated can lead to constructing control charts that look strange. But using some of the things I mentioned, hopefully you can see that these “strange” control charts actually reveal quite interesting information about what is going on (and what to do about it). In the last article I left you with a weird looking control chart to see if you could figure out what was going on in the process. Instead of throwing out the chart and concluding that “SPC doesn’t work here,” let’s take a look at that and see what we could have learned about the process.
|
ADVERTISEMENT |
Here is the X-bar and R chart similar to the one I left you with last time:
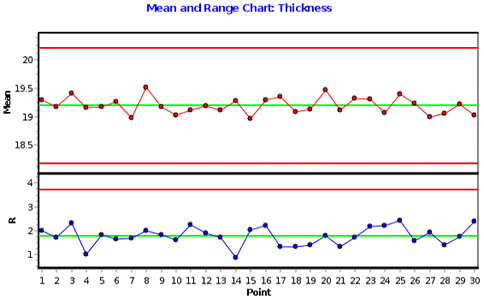
Figure 1 - A Strange X-bar and R Chart
…
Comments
SPC works.
SPC charts are great tools, but like any other tool, one should use caution when using them.
The basic requirements for using SPC charts are that the process is statistically stable and that the data is noramlly distributed.
In the case that was presented, the later requirement is no met.
I digitized the data from the 5 location charts and found that at each location the data is normal, but when you pool the data the distribution is definitely not normal.
The fact that the population is not normally distributed doesn't mean that we can not use SPC charts. There are different ways of dealing with this type of situations and I'll be happy discuss them (if there is any interest).
Best ,
Michael Tzori
normality and the process behavior chart
In his book titled "Normality and the Process Behavior Chart", Dr. Donald Wheeler says..."Three-sigma limits are sufficiently general to use with all types of data. Therefore, we do not have to wait until our data are "normally distributed" before we use three-sigma limits. Nor do we have to transform our data to make them "more normal". So neither the computations nor the use of three-sigma limits establishes a rigid link between the process behavior chart (control chart) and the normal distribution."
Besides, SPC charts do not require the process to be statistically stable. In fact, we use them in order to know when a process is stable or is not.
Thanks for reading and
Thanks for reading and replying!
Actually GMARCH and Jose...
Dr. Wheeler is a great guy, but his ongoing notion that normality is not needed for individuals charts is dead wrong (and demonstrably so). (Of course, x-bar type charts are less sensitive to departures from normality due to the central limit theorem.) Individuals charts are highly susceptible to producing alpha error (adjusting the process when it doesn't need it) and beta error (missing a process shift when it occurs) with departures from normality.
One can sympathize with the attitude, "Ennh, well assuming normality when it really isn't is close enough, and I will take the cost hit in unnecessary adjustments and missed signals in order to avoid having to do those hard [sic] normality tests and those difficult [sic] adjustments to the chart"... if one is in the 1970's and doing hand calculations. However, with modern software, these are easy to do, so why not do it the right way and save yourself money and aggravation?
Testing for normality is ALWAYS important when you get to measuring capability, regardless of chart type since those indices are calculated on the raw data, not the random sampling distribution of the averages. (Unless, of course, your customer cares about your ability to hit specs on average - NOT!) If you didn't take distribution shape into account, you would calculate your capability indices from formulae that assume normality from an estimate of the standard deviation that itself is generated from the theoretical distribution of a dispersion statistic assuming a normal distribution! That is crazy talk! The resulting "capability" will have nothing to do with your actual ability to meet specification. (You could use process performance metrics to quantify past performance which are kind of independent of shape and state control, but you can't calculate capability, which is a statement about future performance...)
And believe me, Deming and Shewhart knew full well the dependencies of the INDIVIDUAL charts and capability indices on the assumption of normality. (My old boss and now colleague Dr. Jeff Luftig worked for Deming at Ford and he is mentioned in Out of the Crisis if you want to look it up.)
Now on to Michael's comment...
As the other comments pointed out, SPC is the tool with which we determine if a process is in control - it would be odd to require a process to be in control before using the tool to determine if it is in control! However, it is true that if the chart indicates a process is out of control, you can't predict what the process is going to do in the future, nor can you use the estimated standard deviation nor can you calculate capability indices because you have no clue as to what it is going to do next. What you CAN and SHOULD do is use the control chart to identify and eliminate the sources of unexpected variation that is throwing it out of control. (Which is another reason why when using the individuals chart it is so important to check for normality - if the process is in control and non-normal, you will end up trying to chase down and trying to fix "differences" that are actually part of the random distribution.)
As above, the central limit theorem does protect you against non-normality of the population if you are using one of the x-bar type charts (the bigger the sample size, the more non-normal the population can be). But it is easy to adjust an individuals chart for non-normality, and it is just as valid once it is. Many processes in real life are totally in statistical control and non-normally distributed, so an individuals chart adjusted for whatever non-normality you have will still give you what you want: a heuristic for determining when to react and when not to. Plus, you can calculate capability for these non-normal but in control processes.
Michael, if you re-read the article, I think you will see why the aggregate data are non-normal - it is the sum of five (or three) normal distributions with different means (so it is probably platykurtic). The correct approach is to plot each "stream" on an individuals chart (and as you say, the streams are normally distributed so we can use the default calculations for the limits). In fact, even if the aggregate data happened to pass a normality test (beta error!) we STILL would not want to put the data on an x-bar and R chart because of the out of control condition on the means indicates something weird about the sources of variation. And don't forget that we also want to continue our investigations into why there is that difference across the width.
SPC Requires Normal Distributions?
As Wheeler has done such a good job pointing out, Shewhart never did say that a normal distibution is required. In fact, he used the Camp-Meidel Inequality to base his work on, which is applicable to any data stream.
And I agree with the previous comment, that one of the reasons for an SPC chart it to detect process instability, so how can you require statistical stability?
Add new comment