Social Sharing block
As I’m writing this, our first big snowfall of the year is piling up outside and it is –10°C (15°F). This brings to mind the many times my grandfather told me of how he walked to school in winter uphill (both ways) with no shoes. So I wondered, will I be able to spin the same yarn for my girls and tell them about how much colder it was when I was young? And could granddad have been exaggerating about more than the fish he caught? So (of course) I did what any data-geek would do and downloaded the data. Let’s take a look and see how this time series pertains to Black Belts.
Sometimes a Black Belt is faced with the question of whether a process is on target. Perhaps you’re coating electrodes with gold and want to make sure that you aren’t giving away the precious stuff, or perhaps your tech-support group wants to know if they’re meeting their objective of an average hold time of 50 minutes before answering the call. (Just kidding.)
We can easily answer this with a hypothesis test. We select the time period, and then perform a one-sample test to see if that data set could have come from one with the average we hypothesize. But what if I’m really interested in adjusting the process when I have sufficient information to determine that I’m off-target? Do I just keep doing a one-sample hypothesis test? Well, consider if you’re on target for a long time, but then your current process average shifts up. How much will this affect the average of the total data set? The previous data at the old average far outnumber the data points for the new average, so the mean of the total data set is only affected a tiny bit at first. The trick is in selecting the time period for the hypothesis test, and if you don’t have reason to determine the break point, you can get vastly different answers for different snapshots in time. What we are really interested in is trends.
Could we use a control chart? Let’s say that the data are individual observations, like annual average-temperatures. We can hypothesize that the average annual temperature is like one of our processes: it has a grand average and variation around that average. If this process is stable, the variation should be quantifiable.
I downloaded the Historical Climatology Network numbers for Boulder, Colorado, (just down the road from me) from 1893 to 2005 (the most recent year in the database). I’m using the Urban Heat-Adjusted numbers to account for the slight increase in recorded temperature caused by urbanization.
Individual and moving range charts are highly sensitive to deviations from normality, so the first thing I did is check that.
|
n |
(A-D)A²* |
p |
(S-W)W |
p |
(L-M)r |
p |
Skew. |
p |
Kurt. |
p |
|
113 |
0.487 |
0.232 |
0.985 |
0.247 |
0.245 |
0.122 |
0.351 |
0.120 |
0.098 |
>.10 |
With the p-values for all the tests above an α of 0.05, we conclude that the data can be modeled reasonably well by the normal distribution, so we are allowed to use the unmodified control limits for the control chart.
If I plot the data on an individuals and moving range chart, I get the following graph:
|
Figure 1. X & MR Chart with μ = X-bar |
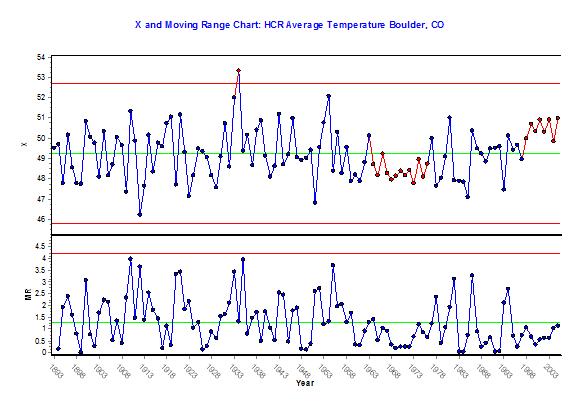 |
As usual, first we look at the dispersion chart. With the moving range, we look only for points outside the upper control limit (because the moving ranges aren’t independent), and conclude that, as far as we can tell, the year-to-year variation is predictable.
Looking at the individuals chart, we see three unusual patterns. The first is that the year 1934 in Boulder was abnormally warmer than expected. (Personally, I think it’s because that is the year that Cole Porter’s Anything Goes heated up Broadway. Not sure how it got to Boulder, though.) The next is a run below the mean starting in 1964 and ending in 1976. (Perhaps the Summer of Love was just cuddling to stay warm.) Finally, we see a run above the mean starting in 1998 and continuing to the end of the data set.
Hmm, well I don’t know about you, but I sure don’t see any indication that it was colder in my grandpa’s day than it was when I was walking to school (1974 to 1990 if you count college).
If the data were from a manufacturing process, say coating thickness, we would reach the same conclusion looking at the chart. We would have some things to investigate, particularly the run at the end.
However, individual charts are notoriously poor at detecting small shifts in the average in a reasonable amount of time. If you are using ±3σ limits, even a massive shift of 3 standard deviations in the real mean has only a 50-percent chance of being detected on the first point. Also, the purpose of a control chart is to signal when there is sufficient evidence that the process has shifted, not really to determine if it is on target. You could, for our discussion, force the chart calculations to put the limits at a target. For our coating example, it would be the target thickness. For Boulder’s temperature, let’s use the average temperature from the beginning of the data set until 1900 (when my grandpa was born) or 49.00625. This way we can compare what I’m going to talk about later, and I won’t get accused of cheating.
|
Figure 2. X & MR Chart with μ = 49.00625 |
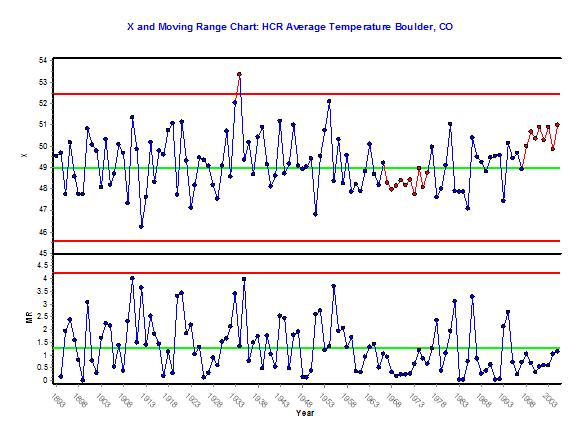 |
This doesn’t change our previous conclusions. (There was a new pattern of unexpectedly low variability around the mean, but because the mean was arbitrary, I don’t give it much credence.) This will allow us to compare it to the next chart we’re going to do.
If we take the average of the last run and compare it to the average of the rest of the data, I might actually get to tell my daughters that it was colder when I was a kid! By more than a Fahrenheit degree! With that run in there, I might even convince myself that it was colder, on average, when I was a kid than it was when my granddad purported to walk to school uphill.
However, if our purpose is to detect even a subtle shift as early as we can, the control chart is not our tool of choice. For time series, we do have another choice, which is frequently neglected by Black Belts, but straightforward to use. It is the cumulative sum chart.
This chart (also called cusum) takes the cumulative difference off of the target for each point and adds them together. If the process is smack on target, the cusum will go up and down around zero. If the process is consistently off target, even by a tiny amount, that small difference in average will keep adding up. At some point, that difference will be enough to trigger a signal.
This is a very different chart than a control chart. If the average is a little off target, you will see an ongoing trend up. If the average comes back on target, the cusum will stabilize at that new sum (because the average added amount is zero), and if the process goes below average, you will see a trend down.
A cusum is a hypothesis test, so we need to choose an α (Type I error). A usual α is 0.05, though with cusums you can see α go much lower if the price of reacting is large compared to the price of missing a shift. We can choose a β (Type II error) as well, but it makes such a small difference for reasonable numbers it doesn’t even show up in the calculations. We also need to choose k, which relates to the magnitude of the shift we want to detect. This factor varies between 0.5 and 1.0, where the magnitude that is easily detected is 2kσ (though keep in mind that even a tiny bit off of target will eventually add up to a significant amount). Sigma here is our old friend the standard deviation. Because the data seem to be modeled adequately by the normal distribution, we can take the estimate of σ from the average moving range as a robust estimate of the process variation, or 1.383, so with a k = 0.5, we have a reasonable ability to detect a shift in average of about that same amount.
The last thing I need is a target temperature, so I chose the average temperature from 1893 to 1900 (you see now why I chose that average for the individuals chart). For a production process, it is easier as you choose your target or nominal.
Now in the old days, we would construct a v-mask and… but that’s complex. Instead, I will use the algorithm in Donald J. Wheeler’s Advanced Topics in Statistical Process Control (SPC Press, 2004), which I put into an Excel spreadsheet for my students.
|
Figure 3. Cusum chart, red points indicate a shift according to Wheeler’s algorithm, yellow points indicate the partial sums in excess of the critical value. |
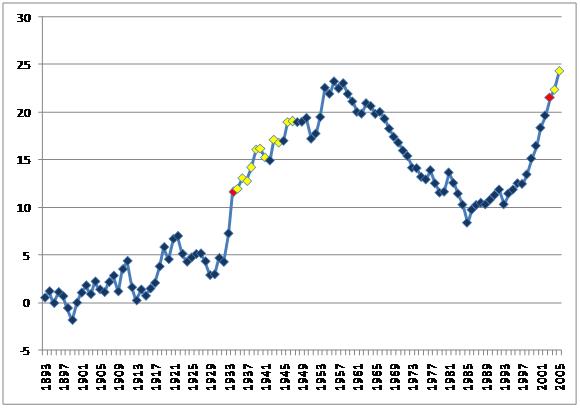 |
You will notice that there are no control limits. At the beginning, you can see the points bounce up and down around the target, which makes sense since we chose that average as the target. Starting in 1901, though, the cumulative sum doesn’t drop back below zero. Still, this might be due to chance, until the cumulative sum reaches a critical value. (We can’t use a run rule as in control charts, because the data aren’t independent. For example, one big spike could lead to a long run of cumulative sums above zero, even if the process immediately went back to target.) Using Wheeler’s algorithm, the point where the cumulative sum reaches significance is in 1934 (indicated by red). Now scroll back to the individuals chart and you can see that you never would have guessed that there was a warming trend confirmed in 1934 (there is only a spike there) and continuing to the early 1950s, and possibly starting as early as 1901, right after our average was taken.
Back to the cusum chart. Keep in mind what is going on here: each year that is below the target goes down from the previous point. Each year that is above the target goes up from the previous point. So, we see the overall warming trend (the slope is going up) but with some plateaus where the average was close to the target. The trend tops out in the 1960s and the cusum starts to slope down as the run of lower-than-target temperatures we saw in the individuals charts come into play. But after bottoming out in 1985, we see an increasing trend that becomes steep in 1996 and continues on up again due to that run above the mean that we saw in the individuals chart. Wheeler’s algorithm sends out a signal in 2003.
Conclusions
The story that the cusum gives us is more nuanced than that of the individuals chart. We see evidence of an early warming trend stabilizing somewhere between 1934 and 1965, followed by a cooling trend, and another warming trend on the end with a higher rate of change. With the control chart, we saw a one-year spike in temperature and two eight-year runs.
If this were a process, you would have reacted at about the same time using both charts. However, the control chart is telling a different story, one of sudden changes and then, apparently, back to what we expect. It’s also worth noting that you get four extra signals using the Western Electric rules on the individuals chart, but these exceptions don’t seem to add much to understanding the process in this case.
In situations where the shift is subtle and ongoing, the cusum will signal a reaction far ahead of an individuals chart. In cases where the shift is large (say, 2σ or more) the cusum doesn’t buy you a lot more than the individuals chart. Never use a cusum chart without a control chart, though. They are there for two different purposes. The control chart signals instability events and shows you the real output, while the cusum is sensitive to being off target. They answer two different questions. In the modern computer era, there’s no reason not to run both charts if subtle shifts in the average will cost you money.
So what do we conclude? It looks to me that my granddad and I had about the same temperature to walk in (though I admit I had shoes), but that my school-walking days just happened to be the end of a downturn subsumed in an overall trend up. So I do get to tell my daughters that it was colder when I walked to school, on average. And I also have to tell them that, if the process continues without adjustment, their kids will be walking to school in much warmer weather.
But I could be wrong.
Please post your questions and comments at the Discussion Board. I’ll post a link there to the data I used if you want to mess around with it.
Note that the data were obtained from this source: Williams, C.N., Jr., M.J. Menne, R.S. Vose, and D.R. Easterling. 2007. United States Historical Climatology Network Monthly Temperature and Precipitation Data. ORNL/CDIAC-118, NDP-019. Available on-line [http://cdiac.ornl.gov/epubs/ndp/ushcn/usa_monthly.html] from the Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory, U.S. Department of Energy, Oak Ridge, Tennessee.
Add new comment