Thu, 09/09/2010 - 08:51
Social Sharing block
Body
Last month I wrote about how the random sampling distribution (RSD) of various sample statistics are the basis for pretty much everything in statistics. If you understand RSDs, you understand a lot about why we do what we do in hypothesis testing, inferential statistics, and estimation of confidence intervals. Understanding RSDs gives you a huge advantage as you seek to use data in business, so let's take a closer look.
|
ADVERTISEMENT |
First, a brief refresher from last month. We have the big honkin' distribution (BHD), which is the distribution of the entire population of interest as shown in figure 1:
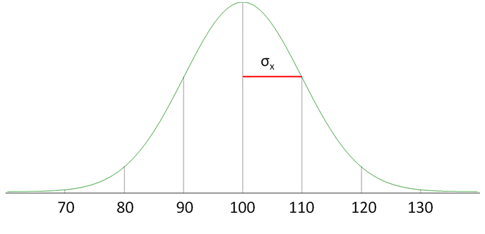
Figure 1: Big honkin distribution (BHD) of the entire population of interest
…
Want to continue?
Log in or create a FREE account.
By logging in you agree to receive communication from Quality Digest.
Privacy Policy.
Comments
Product distribution
Your first assumption is meaningless. We never know the product distribution. A vast amout of data is required to even roughly estimate it and the process will change during any attempt to estimate it.
Meaningless...or Masterful?
Hi again ADB, and thanks for reading.
.
This is what is known technically as a "simplification for instructional purposes." :) No actual products were harmed during the writing of this article, which was intended as an introduction to RSDs and why they are so important. So if my pretend process happens to be normally distributed, so it is.
.
However, to your point. Real processes do tend to have distributions of some sort, at least at the level to where they are, in Box's words, useful models. Thankfully, the physical limitations of the universe mean that we don't often find processes that are totally random walks. There is often a confluence of influences that result in knowable distributions: the "memorylessness" of the exponential and its relation to the Poisson, the binomial distribution of a Bernoulli process, the many small sources of random variability that result in a normal distribution, all of these can be useful models for real process behavior. As long as you don't forget that they are models. But in business, we often have to make assumptions in order to make decisions - otherwise we end up in analysis paralysis never making a decision because nothing is *exactly* normally distributed, or we make decisions based on our gut in the absence of any data or analysis. (We do need to test the validity of our assumptions, though.)
.
A common error made about hypothesis testing is that we are saying a process is *really* distributed as something mathematical. We are only using useful models (hopefully with some theoretical basis in reality) to help reduce the error rate of our decisions and give us a repeatable way of making decisions, rather than relying on "I believe it must be so" reasoning. When I teach statistics, I test, in order, "shape, spread, location." If the shape is reasonably approximated by some known distribution, or can be transformed as such, then the probability of us making a bad decision due to that assumption is low. If it cannot, then maybe we can use some other non-parametric test to still help with our decision-making. If I took all the decisions I have made using statistics and knew which ones were "right" and "wrong" I would grant you that the number wrong would be some amount higher than the declared alpha error level, due to differences in assumed distributions, unknown systematic errors and threats to external validity, uncontrolled factors, etc. But not much higher, and much more correct than if managers used their gut to make their decisions for them.
.
Of course, if we have a process where we have control charts on all critical process variables, and we react as they go out of control, then it is pretty likely that we do see a nice, model-able, useful distribution of some sort. And a cool thing about RSDs of means is that, regardless of the distribution of the individuals and given a large enough sample size, the RSD tends to be normally distributed. So we are probably not far off when we make decisions based on a sample with a t-test, for example.
.
When we get stuck modeling a process empirically (like using the Johnson family to fit a distribution to sample statistics) then things do get nasty, and that is my least-preferred way to make decisions. But even so, sometimes decisions must be made, and at least I have a repeatable, gut-feel-independent process I followed in making them. I just need to keep in mind that that model is highly provisional and subject to rather large errors.
Weld Improvement Starting Point
Rather that designing an experiment and evaluating distributions, wouldn't a better approach begin with plotting the weld strength data in the order of production to see if only one distribution actually exists?
Rich
Absolutely Right!
Yep, if we were doing this in "real life" you would need four things for each data set before doing any experiment: shape, spread, location, and through time variability. The first three are shown in various ways and described by statistics, the last one by a control chart. In the absence of control (significant changes in shape/spread/location through time), it becomes much more difficult (though not impossible) to perform and analyze an experiment. If it is out of control, you'll end up with larger sample sizes, possibly some blocking, maybe variable limitation (and its threat to external validity), and always run the risk that that effect you think is so great was actually a special cause you don't understand. So while you can run an experiment on an out-of-control process, you had better know about that before hand to try to mitigate.
.
Buuuuut, since I am really only using this process as a vehicle for showing you how to use RSDs, and since my editors already give me grief about the huge articles I write... :) But understanding BHDs and RSDs is critical in understanding how to design and analyze any experiment.
.
Actually, if this were real life, I probably would also be looking at existing data (if it existed) and doing some data mining to see if I could find some factors to put in my experiment, rather than just trying Bobby Jo's technique, but again, I am trying to show you RSDs. And maybe Bobby Jo is the CEO's daughter...
Hi again ADB, and thanks for reading.
But then again, you could be wrong.
Six Sigma Heretic Strikes Back!
Hey! A reader of my first columns! (I used to sign all my columns that way...until it got too annoying even for me.)
.
Indeed, as the scientific method has taught us, everyone has to humbly admit that some amount of what they think they know is wrong. Being wrong is an opportunity to learn something new! Just because someone writes an article or a book, does not put them above question.
.
Reality is a harsh place to live, but it beats the alternatives...
.
Keep on learnin'!
thanks great article
Just got a chance to read your article and wanted to thank you for making something I've learned over and over and over again the easiest to learn over again. I've been teaching a clinical research methods course for the last 5 years and I always received at least one comment that someone doesn't like how I explained power and sample size. I give them an article on the topic, a lecture, and we go to a web site to foul with changing alpha, effect size, etc and the result ends with some not getting it. (I always consider one complaint means more than one has that same complaint.) I always consider whether I know the subject well enough so I think your article solidified some points and look forward to sharing your excel sheet in class. Maybe we (me and the students) will make some progress this next time out, thanks again.
Thanks Karen!
Honestly Karen, that is the highest accolade I can receive for an article like this. In my experience, sample size is not well understood by applied researchers (including Black Belts and Master Black Belts) and the cost of decisions made in the absence of such understanding must be staggering.
.
Good luck, and let me know how it goes!
Add new comment