Social Sharing block
Whenever the original data pile up against a barrier or a boundary value, the histogram tends to be skewed and non-normal in shape. In 1967 Irving W. Burr computed the appropriate bias correction factors for non-normal probability models. These bias correction factors allow us to evaluate the effects of non-normality upon the computation of the limits for process behavior charts. To understand exactly what these effects are, read on.
Background
Before we can discuss the computation of limits for non-normal probability models, we will need to have a way to quantify the uncertainty in the computed limits. The curve that does this is given in figure 1.
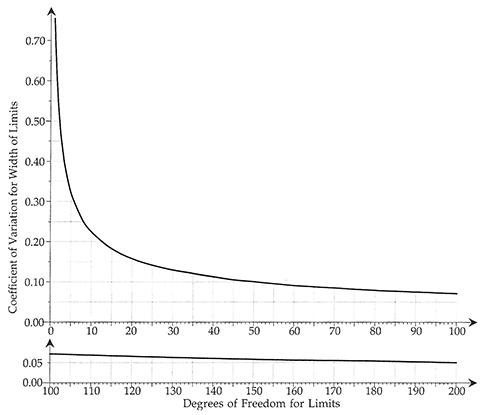
Figure 1: Uncertainty and degrees of freedom for process behavior chart limits. Click here for larger image.
{kind=link}
…
Comments
Why not try to identify the actual distribution?
The Burr approach does seem complicated, and a simpler and more accurate approach is to use the actual underlying distribution, if it can be identified. Noting that Minitab and StatGraphics can fit these other distributions--an option that wasn't available in Burr's day--there is no practical obstacle to doing this.
The first step is to identify the likely distribution. For example, if a certain characteristic is known to follow the Weibull distribution or extreme value distribution (the latter for failure at the weakest point), try that distribution first. My experience with actual data is that impurities such as trace metal concentrations follow the gamma distribution. This is not surprising because contaminants, impurities, and so on are undesirable random arrivals. We know random arrivals follow the Poisson distribution, and the gamma distribution is the continuous-scale counterpart. My article ""Watch Out for Nonnormal Distributions of Impurities," Chemical Engineering Progress, May 1997, pp. 70-76" discusses this further, and applies the gamma distribution to actual trace metal data.
Then fit the process data to the distribution in question, and perform goodness of fit tests (quantile quantile plot, Anderson-Darling statistic, chi square test) to make sure we cannot reject the null hypothesis that we have selected the right distribution. Note also that these tests will almost certainly reject the normal distribution.
Then use the fitted distribution to find the 0.00135 and 0.99865 quantiles for the control limits although, in the case of something like a gamma distribution in which we want zero of whatever we are measuring (such as contaminants), we can dispense with the LCL.
The Central Limit Theorem may let us use a normal distribution (traditional Shewhart limits) with a big enough sample, but we MUST use the actual distribution to calculate the process performance index. This is because individual measurements, as opposed to sample averages, are in or out of specification. The Automotive Industry Action Group sanctions this approach, along with another that is apparently almost as accurate. Reliance on the normal distribution, e.g. PPU = (USL-mean)/(3 sigma), can create a situation in which our purportedly Six Sigma process is delivering 100 or even 1000 defects per million opportunities.
All of this can be done in minutes in StatGraphics or Minitab. These programs will fit the data, and then perform the goodness of fit tests (Minitab does not apparently do the chi square test, which quantifies how well the actual histogram matches that of the fitted distribution). They will also use the actual distribution to give the process performance index. StatGraphics will create a control chart with the correct limits for the distribution in question.
If somebody has non-proprietary data they are willing to share, e.g. impurities, pollutant concentrations, or anything else that could easily follow a gamma distribution (or other data for which the underlying distribution is known), they would make a good case study.
Caveat for the gamma distribution and impurities
When we deal with impurities that are measured in parts per million (or even less), we run up against the issue of the lower detection limit. If, for example, the LDL is 0.1 ppm, "zero" can mean anything from 0 to 0.1 ppm. This requires the use of methods similar to those for censored reliability tests, in which not all items have failed by the end of the test, but in this case censoring is at the bottom rather than the top of the distribution. Off the shelf methods are available for doing this.
Comments
What is this? A filibuster? 106 lines of commentary out of a total of 124 lines come from one source!
To repeat the quote from Elton Trueblood that I have at the begining of Understanding Statistical Process Control,
"There are people who are afraid of clarity because they fear that it may not seem profound."
oh boy
I enjoy statistical math, I really do. I could get lost in my computer for hours and days with it...but I don't get paid for it. I get paid to prevent and solve quality problems in a for profit company. So I need practical approaches to industrial problems. So there are three issues that I see in this clash of beliefs regarding SPC. First is the difference in theoretical precision and practical value. The second is related but slightly different; the difference between theoretical models and practical reality as it effects the use of common statistical calculations. The third is a very simple communication issue.
I will start with the third as it is easiest: The difference between setting control limits and using them to gain insight. This article – and indeed many articles by Dr. Wheeler - deal with using control limits to gain insight into the stability of a process and/or clues as to why the process appears unstable. In these instances Dr. Wheeler is correct; calculating control limits for insight into time series data is invaluable. Dr. Levinson is partially correct that we should not set control limits for an unstable process. There are exceptions to this of course. One is that very few processes are ever stable for any substantial amount of time – which is one reason why we need control limits: to detect excursions as early as possible and take appropriate action to reverse the event and prevent recurrence thereby improving the stability of the process. A second reason is that not all processes that appear to be ‘unstable’ through traditional subgrouping (sequential pieces) are unstable – or incapable. They may simply be non-homogenous.
This leads us to the second issue. This non-homogeneity is quite common and can be quite benign in today’s manufacturing processes. Non-homogenous, yet capable processes are exactly why the concept of rational subgrouping was developed. Yet in the theoretical statistical models for most of the common statistical tests of significance, there is an assumption that non-homogeneity is wrong and must be corrected. The statistical models give mathematically correct, yet practically wrong answers in the presence of non-homogeneity. Non-homogeneity also ‘looks’ like an assignable cause – one can clearly see the changes related to cavity to cavity or lot-to-lot differences so they should be considered as ‘out of control’ and due to assignable causes right? But if we think about it, we could apply the same logic to piece to piece differences that exist in a homogenous process: we can clearly see it so it must be assignable and easy to fix right? Piece to piece variation that is clearly visible is common cause variation – one must understand the true causal mechanism of the variation in order to ‘fix’ or improve it, otherwise we are tampering. The same logic must apply to other components of variation. Without understanding true cause we are only tampering. Non-homogeneity is not a sign of instability. It is simply a sign that other factors are larger than the piece to piece variation components. George Box wisely said “all models are wrong; some are useful”.
And now for the first issue. Dr. Levinson appears to be placing value on statistical precision. Dr. Wheeler is placing value on practical use. If one values statistical precision, Dr. Levinson is correct. If one is looking for an actionable answer to a real world problem Dr. Wheeler is correct. While there is value in statistical precision, in the industrial world, we only need enough statistical precision to gain insight and make the right decisions. If more precision doesn’t add value to this process, it is only of academic interest. We must remember that a very precise estimate is still an estimate. It may very well be precisely wrong. Ask yourself: from an everyday, real world perspective, does a very statistically precise estimate of a .03% chance of mis-diagnosing an assignable cause provide you with truly better ability to detect and improve excursions than a 5% chance of mis-diagnosis? And perhaps more importantly, is that improvement worth all of the extra time? To quote another famous statistician, John Tukey said that “an approximate answer to the right question is worth far more than a precise answer to the wrong question”.
Practicality and precision
Robert Heinlein wrote in Starship Troopers that, if you weigh a soldier down with a lot of stuff he has to watch, somebody a lot more simply equipped, e.g. with a stone ax, will sneak up and bash his head in while he is trying to read a vernier. This certainly applies to complex statistical methods (e.g. fitting a gamma distribution to data) if you don't have a computer. This is why we have, for decades, used normal approximations to the binomial and Poisson distributions for attribute control charts even though these approximations work very poorly unless we expect 4-6 nonconformances or defects per sample.
The traditional 3-sigma limits will admittedly work more or less even for non-normal distributions but, if they give you the wrong answer 1 percent of the time rather than 0.135 percent of the time (the process is out of control, when it is actually in control), the production workers will find themselves chasing false alarms and possibly making adjustments (tampering) when no adjustments are needed. Things get a lot worse if you calculate a process performance index under the normal distribution assumption when the process is non-normal, becuase the estimate of the nonconforming fraction can then be off by orders of magnitude.
"Non-homogeneity also ‘looks’ like an assignable cause – one can clearly see the changes related to cavity to cavity or lot-to-lot differences so they should be considered as ‘out of control’ and due to assignable causes right?" raises two additonal issues. Systematic differences between mold cavities are not an out of control situation, tney are a multivariate situation for which well-established control methods (T squared chart) are known. That is, while each cavity does not produce exactly the same mean, their performance is correlated.
Between-batch variation also is a known issue, and control limits can be calculated that reflect both it and the (often smaller) within-batch variation. This, in fact, is often responsible for the difference between Cpk (short term variation, as calculated from subgroup statistics) and Ppk (calculated based on long-term variation). When Cpk > Ppk, the subgroups clearly do not reflect all the variation that is present.
KISS principle
I often wonder if folk like Levinson have shares in Minitab. No matter how much wonderful and detailed explanation Don gives, they just don't seem to get it.
People who use control charts
There seems to be two types of folks who use process behavior charts. Those actively working on improving a manufacturing process or adminstrative system and those who don't. For those folks who use them as part of their every day work, we know how useful they are. We don't bother with all the statistical assumptions because we don't have to. They work well and help us improve our products and systems. That's ALL we care about. We're not mathamaticians nor statistians. We are users of the charts.
I often wonder if the people who write articles on SPC ever really use them in practice.
Rich D.
Trend charts vs. SPC charts
There is nothing wrong whatsoever with using a trend chart that does not rely on statisitcal assumptions, e.g. like Figure 8 in Don Wheeler's article at http://www.qualitydigest.com/inside/quality-insider-article/myths-about…. This trend chart shows clearly that something is wrong about the process regarless of its statistical distribution.
As for using SPC in practice, that is exactly why I took the time to write numerous articles on SPC for non-normal distributions. I found that what I learned in the textbooks (plus/minus 3 sigma control limits) did not work in the factory.
Furthermore, it is not optional, but mandatory, to use the actual underlying distribution when calculating process performance indices (with their implied promises about the nonconforming fraction). E.g. Figure 1 of Wheeler's article for modulus of rupture for spruce, and slide 21 of http://www.slideshare.net/SFPAslide1/sfpa-new-design-value-presentation… shows a similar distribution for pine. The distribution is sufficiently bell curve shaped that you might get away with 3 sigma limits for SPC purposes (assuming SPC were applicable to this situation), but you sure wouldn't want to use a bell curve to estimate the lower 1st or 5th percentile of the modulus of rupture.
You can also run into autocorrelated processes, e.g. quality or process characteristics in continuous flow (chemical) processes. As an example, the temperature or pressure at a particular point is going to be very similar to the previous one. Traditional SPC does not work for these either.
The only thing you risk by using the wrong distribution for SPC is a (usually) higher false alarm risk, i.e. the workforce is chasing far more than 0.00135 false alarms per sample at each control limit. If you assume a bell curve when estimating the Ppk for something that follows a gamma distribution, though, your nonconforming fraction estimate can be off by orders of magnitude.
More on this from Quality America
http://qualityamerica.com/Knowledgecenter/statisticalinference/non_norm…
"Software can help you perform PCA with non-normal data. Such software will base yield predictions and capability index calculations on either models or the best fit curve, instead of assuming normality. One software package can even adjust the control limits and the center line of the control chart so that control charts for non-normal data are statistically equivalent to Shewhart control charts for normal data (Pyzdek, 1991)." StatGraphics can do this, and my book on SPC for Real World Applications also discusses the technique in detail.
This abstract for a paper also raises the issue: http://papers.sae.org/1999-01-0009/
"The application of SPC to an industrial process whose variables cannot be described by a normal distribution can be a major source of error and frustration. An assumption of normal distribution for some filter performance characteristics can be unrealistic and these characteristics cannot be adequately described by a normal distribution."
Reply for Levinson
As I explained in "Why We Keep Having 100-year Floods, (QD June, 2013) trying to fit a model to a histogram is meaningless unless we know the data in the histogram are homogeneous and that they all came from the same process. This is the question that is only addressed by a process behavior chart. Trying to use your fancy software to fit a model to garbage data will simply result in garbage dressed up in mathematics.
Let the user beware. Your software has no common sense.
If the process is out of control, we can't set control limits
If the date are garbage (e.g. from an out of control process or, as shown by the 100 year hurricane example, what are essentially two different processes), NO model will give us a valid control chart or capability index. E.g. a manufacturing process that behaved like Figure 3 in the hurricane article would clearly be an example of a process that has changed, e.g. to a change in materials rather than season. We could not set valid control limits for that process either.
This is why, in addition to performing goodness of fit tests, we must also make a control chart of the data to make sure nothing of this nature is happening. Figure 3 of the hurricane article shows clearly that we have a bimodal (at least) "process," each segment of which follows its own Poisson distribution.
If the data are homogenous, though, the actual underlying distribution must be clearly superior to any normal assumption or approximation.
Myth Four
In "Myths About Process Behavior Charts," QDD September 8, 2011, I refer to the argument you have just presented as Myth Four. This article deals directly with the arguments you are presenting here, so anyone who wishes to dig deeper should find this article interesting.
Requirement for state of control
Per the AIAG SPC manual (2nd ed, page 59)
There are two phases in statistical process control studies.
1. The first is identifying and eliminating the special causes of variation in the process. The objective is to stabilize the process. A stable, predictible process is said to be in statistical control.
2. The second phase is concerned with predicting future measurements thus verifying ongoing process stability. During this phase, data analysis and reaction to special causes is done in real time. Once stable, the process can be analyzed to determine if it is capable of producing what the customer desires.
============
This suggests that the process must indeed be in control before we can set meaningful control limits. This is not to say that we cannot plot the process data to look for behavior patterns, e.g. as shown in Figure 6 of http://www.qualitydigest.com/inside/quality-insider-article/myths-about…. It is easy to see just by looking at this that there is a problem with this situation.The AIAG reference, in fact, says the control statistic(s) should be plotted as they are collected.
It adds, by the way, that control limits should be recalculated after removal of data from subgroups with known assignable causes--that is, not merely outliers, but outliers for which special causes have been identified. Closed loop corrective action should, of course, be taken to exclude those assignable causes in the future.
Add new comment