Social Sharing block
I was teaching a class and asked participants to create a control chart of an indicator that was important to them. A lab supervisor presented me with a chart on the number of procedures her department performed and told me that it wasn’t very useful.
|
ADVERTISEMENT |
She wanted to use the chart for staffing purposes, but the wide limits were discouraging to the point of being ridiculous:
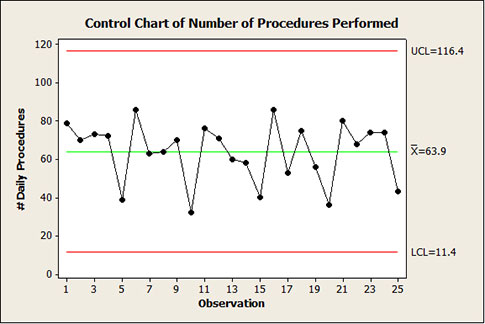
I know that a lot of you have access to software with the classic Western Electric special cause tests programmed in. In this case, none of them were triggered. On the surface, the chart is exhibiting common cause. For what it’s worth (and as you will see, it isn’t worth much), the data also “pass” a Normality test with a p-value of 0.092. Lots of statistics. And the subsequent action is...?
…
Add new comment