Whenever we present capability indexes the almost inevitable follow-up question is, “What is the fraction nonconforming?” What this question usually means is, “Tell me what these capability indexes mean in terms that I can understand.” These questions have resulted in multiple approaches to converting capability indexes and performance indexes into fractions nonconforming. This article will review some of these approaches and to show their assumptions, strengths, and weaknesses.
The empirical approach
In order to make the following discussion concrete, we will need an example. We shall use a collection of 100 observations obtained from a predictable process. These values are the lengths of pieces of wire with a spade connector on each end. These wires are used to connect the horn button on a steering wheel assembly. The upper specification for this length is 113 mm.
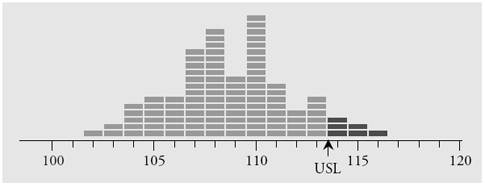
Figure 1: Histogram of 100 wire lengths
…
Comments
Practical vs. Theoretical
Thanks again for bridging the gap between the theoretical (i.e., Six Sigma thinking) and the real world. Although he may not like the answer, I would far rather tell my boss our defect rate was less than say, 6.4% (based on real data) than give him some number like 3.4 ppm!!!
Six Sigma
Hopefully this article starts to get through the thick heads of the thousands of companies who have been conned into paying billions of dollars on ridiculous six sigma programs.
Hopefully one day Six Sigma will be sent to history's trash can of global follies. Will there ever be a return to clear thinking ?
Estimating Fraction noncomforming
I am not a statistician but am trying desperately to learn the ropes; I understood this article well until we got to The Probability Approach and Z values; I know about normal distribution, the Standard Normal Table and all but for a novice like myself this article misses the mark. Many times I run into the same problem, that is that knowledgable authors begin by explaining in basic terms and concepts and then as the article goes on they forget their audience (I only assume the novice is your audience) and become too technical and lose me; the novice. Where can I get the Real Dummies guide to these topics where complex ideas are broken down into simple application
No Dummies Guide
I don't know that there is a good "Dummies" guide to any of this...Marilyn Vos Savant demonstrated years ago that many Ph.D. mathematicians are dummies when it comes to probabilities (Google "Monty Hall Dilemma" if you want more info on that). The problem is that probability concepts are counterintuitive for most people. Add to that that most stats teachers and authors only approach stats from three of its inherent problems: probability models, descriptive statistics, and inferential statistics. They give very little, if any, attention to the fourth problem--homogeneity.
If you know the standard normal tables, then you know what Z values are (standard deviation distances from zero in the standard normal distribution). A great guide to some of the concepts in this article is Don Wheeler's "Making Sense of Data." It's pretty accessible. Davis Balestracci's Data Sanity is very helpful, as well.
Sorry About the Confusion.
The latter half of this article was focused on a practice that is widely used and seriously misunderstood. If you can use the first part then that is all that you need to avoid serious confusion. The Binomial Point Estimate is vary easy to compute, and the Wilson Interval Estimate is not much harder. The use of probability models, z-scores, and all that is something that you really do not need in practice. So, hopefully this will relieve some of the anxiety.
More uncertainty
This article is excellent. I didn't realize there is so much uncertainty surrounding these summary statistics. And to think this doesn't even account for sampling and inspection errors.
Rich DeRoeck
Another Eye-opening article!
Great new insight, as usual, Don. I've been doing some work to try to get rid of the "Process Sigma Table" used almost universally in the Six Sigma world. This is just more ammunition.
Education
Thanks for the common sense. I have several thousand users of a software that reports estimated nonconforming fractions. Most of them treat those ppm's as if they were the "real" thing. I've been looking for a way to explain the uncertainity associated with those estimations. May I cite your article Dr. Wheeler? or maybe Mr. Wilson's work?
Estimating the Fraction Nonconforming
Dr. Wheeler should have stated his case for individuals control charts, because this is where many prominent world renowned quality and industrial engineers and statisticians disagree with him in the PHASE II of SPC monitoring. I agree that fitting a normal distribution to everything may not matter much when a process is unstable for several reasons. Any assignable cause will be investigated and the SPC chart will be rerun after the cause is found and the part fixed. Individuals control charts are very sensitive to non-normality. Type II (false alarm) errors occur when fitting a normal distribution to skewed data. A normal distribution is NOT "good enough" when fitting skewed, non-normal data to create an SPC chart. Control limits should be computed from the best-fitted distribution when the data is significantly skewed, not from a normal distribution. Dr. Wheeler infers all probability plots are useless, because he says everyone should fit a normal distribution to all data.
As for fraction-nonconforming, NO ONE chooses a probability model randomly or arbitrarily. Statisticians and Systems Engineers choose the BEST distribution based on a GOODNESS OF FIT statistic, such as the Anderson-Darling statistic, the Kolmogorov-Smirnov statistic, or others. Dr. Wheeler slams Goodness of Fit statistical theories, which have been useful proven tools in modeling and simulations, because these models and simulations are tested over and over and verified. Dr. Wheeler goes against past and present eminent scientists and engineers who use Goodness of Fits and use probability plots every day in their work. Dr. Wheeler also goes against hypothesis testing and using probability plots to weed out bad fits in order to compute fraction nonconforming more accurately.
All probability distributions can be tested for Goodness of Fits to properly model the data; if the normal is the best fitting one, so be it. If not, a non-normal distribution should be used to compute the Probability of Nonconformance (PNC); this is the fraction non-conforming in percent. Assuming a two-sided limit, the Yield = 100% - (total PNC of upper and lower spec limits). Dr. Wheeler failed to note that a best-fitted probability distribution can also have 95% confidence limits, so why compare a badly fitting normal distribution to skewed data and claim it's appropriate? It is not appropriate.
Six-sigma is a process that uses sound and robust statistics to ensure a wider margin of quality for acceptance testing, ensuring zero rework, and shipping products to customers with no returns or flaws. Several companies have saved millions of dollars using a well-planned and implemented six sigma process. What sticks out more than anything else about Dr. Wheeler's comments on fraction non-conforming are the risks in REWORK caused by his assumption of normality in SPC charts and using the Poisson or binomial distribution to compute fraction non-conforming for all cases (using the empirical method). Using the binomial distribution or empirical method of X successes out of N samples is merely using the old bean-counting PASS/FAIL system of the last century: this method gives no information about the probability of rework like a well-fitted probability model does. Also, regarding using 95% confidence limits, is 5% error margin good enough to send products with this fraction nonconforming error margin to the customer? Do aerospace companies want to live with 5% probability of rework???
In summary I think Dr. Wheeler is going against too many well established probability and statistical methods and many statistical and industrial engineering experts by oversimplifying fraction nonconformance to the point of causing rework if companies were to adopt Dr. Wheeler's approach. Rework of course can be translated into dollars as Dr. Genichi Taguchi pointed out. Caution is advised in oversimplifying models thinking they are "good enough" to fit the real world and good enough to avoid rework.
One last note: Businesses and engineering methods and quality suffer due to lazy and uneducated people who hate to do statistics. Six-sigma haters have a point in hating six sigma only when their six sigma program is run by charlatans who do NOT use probability and statistics at all or misuse it. These people should know that common sense mixed with 21st Century engineering and technology, and education in mathematics, gets PROVEN results while others can only speculate and get rework from their SPC programs.
"statistics haters" and other lazy people
David - I'm not disputing that we can often find an appropriate distributional model to predict the fraction nonconforming - often we can. But I think you may have missed Dr. Wheeler's point, which is that many people have leraned the 'dumbed down' version of statistics and many people in industry use them. The situation that Dr. Wheeler describes (the rote appliation of the Normal distribution to predict defect rates when none are are observed becuase the process is stable well withinthe limits) is an epidemic in industry. This epidemic applies not only to the frequency but the severity of its mis-use. You are correct that such people are ignorant - and/or lazy - but yet they continue on in their blissfully ignorant way much like the mayhem guy on the insurance commercials. We need to get thru to them - not you or your organization. Although this behavior is no longer tolerated within my organization, I am continually retraining new hires (fresh out of university and with 35 years of experience) and my suppliers.
Another comment I would make is that although we can determine a suitable distribution, we often don't need to. Will a more sophisticated calculation change the action we need to take? a 5% defect rate calculated simply from the observed defect rate will not drive a different action than using a probability distribution to predict the likely rate to be 5.16% On the other hand I do use fairly sophisticated models on board diagnostic equipment to ensure that even a small percentage of bad runs don't occur...it all depends.
Lazy and Uneducated?
I think I'll stick with the binominal point estamate. Easy to explain, simple to calculate and relies on no assumptions. But then again...perhaps I'm one of those uneducated and lazy folks (NOT).
THERE ARE PEOPLE WHO ARE AFRAID OF CLARITY BECAUSE THEY FEAR THAT IT MAY NOT SEEM PROFOUND.
Elton Trueblood.
Rich DeRoeck
Fraction Nonconforming
Elton and Rich:
For the sake of clarity, I recommend you read: "Statistics Without Tears", or, "The Idiot's Guide to Statistics", or, "Statistics for the Utterly Confused" so in the future, you can simplify your world of statistics. These books can be found at Amazon.com. Profound, these books are NOT, but such clarity and so simple to use, you'll feel like you're back in junior high math class. Enjoy.
David A. Herrera
Add new comment