Social Sharing block
Sometimes when authors try to make a technical concept more understandable, it’s simplified but unfortunately, less accurate.
|
ADVERTISEMENT |
For example, when the developers of Six Sigma wanted to explain control charts and process capability analysis, they needed to include how the signal can be separated from the noise in time-series data. Instead of falling back on terminology used by Walter A. Shewhart, W. Edwards Deming, Acheson J. Duncan and others, they created new terms to explain subgrouping and the within-and-between subgroup variation. Perhaps they felt the old terminology was too abstract and confusing for practitioners. Apparently they chose to skip over important details like what the difference is between a subgroup and a rational subgroup, and deemed “short-term” and “long-term” as sufficient.
“Everything should be made as simple as possible, but not simpler.”
—Albert Einstein
…
Comments
The real origins of Sick Sigma's "Long Term"
The origin of the common Six Sigma "long term" expression is explained in detail below. It came from that farcical "long term drift/shift" of +/-1.5 sigma that forms the "six sigma" of Six Sigma. The clear advice is stick to Shewhart Charts.http://www.qualitydigest.com/inside/six-sigma-article/sick-sigma.html"
...
The +/-1.5 shift was introduced by Mikel Harry. Where did he get it? Harry refers to a paper written in 1975 by Evans, “Statistical Tolerancing: The State of the Art. Part 3. Shifts and Drifts.” The paper is about tolerancing. That’s how the overall error in an assembly is affected by the errors in components. Evans refers to a paper by Bender in 1962, “Benderizing Tolerances—A Simple Practical Probability Method for Handling Tolerances for Limit Stack Ups.” He looked at the classical situation with a stack of disks and how the overall error in the size of the stack related to errors in the individual disks. Based on probability, approximations and experience, he asks:
"How is this related to monitoring the myriad processes that people are concerned about?" Very little. Harry then takes things a step further. Imagine a process where five samples are taken every half hour and plotted on a control chart. Harry considered the “instantaneous” initial five samples as being “short term” (Harry’s n=5) and the samples throughout the day as being “long term” (Harry’s g=50 points). Because of random variation in the first five points, the mean of the initial sample is different from the overall mean. Harry derived a relationship between the short-term and long-term capability, using the equation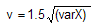 to produce a capability shift or “Z shift” of 1.5. Over time, the original meaning of instantaneous “short term” and the 50-sample point “long term” has been changed to result in long-term drifting means.
to produce a capability shift or “Z shift” of 1.5. Over time, the original meaning of instantaneous “short term” and the 50-sample point “long term” has been changed to result in long-term drifting means.
Harry has clung tenaciously to the “1.5,” but over the years its derivation has been modified. In a recent note, Harry writes, “We employed the value of 1.5 since no other empirical information was available at the time of reporting.” In other words, 1.5 has now become an empirical rather than theoretical value. A further softening from Harry: “… the 1.5 constant would not be needed as an approximation.”
My work with Dr. Mikel Harry on 1.5 Sigma Shift
On October of 2013, I had the pleasure of working with Dr. Mikel Harry on his 1.5 Sigma Shift Theory. The paper that I proofed for him took us a long time to bring together. The theory appears valid, and I would welcome discussion from anyone in the community who would like to review and discuss further with me personally.
Please refer to my website Rent-A-Blackbelt.com for contact information - I look forward to speaking with you about this topic.
Best,
Mr. Manny Barriger, CEO
Rent-A-Blackbelt ®
long term vs short term variation
Good evening everyone!
It may be a silly question but i wanted to ask if there is any chance that the short term variation can be larger than the long term variation! Thanks in advance!!
Short term vs long term variation
Surprise, surprise. Short term variation can exceed long term. I have seen this happen several times but it is not real. It can happen in small samples due to rounding.
--John J. Flaig, Ph.D.
Add new comment