Social Sharing block
In part one we found that the skewness and kurtosis parameters characterize the tails of a probability model rather than the central portion, and that because of this, probability models with the same shape parameters will only be similar in overall shape, not identical. However, since software packages can only provide shape statistics rather than shape parameters, we need to look at the usefulness of the shape statistics.
In part one, we saw that the skewness parameter is the third standardized central moment for the probability model. For this reason, a commonly used statistic for skewness is the third standardized central moment of the data:
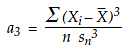
In a similar manner, we shall use the fourth standardized central moment of the data as our statistic for kurtosis:
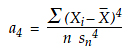
…
Comments
Hear! Hear!
I am going to print out both parts of this article and roll the pages up into a nice, tight roll. Then I'll use it to whack the next Six Sigma geek I see who tries to convince me that data has to be "normal" or "transformed to make it normal" before it can be properly analyzed!!!
Six Sigma idiots
Steve, there is no way I'd call a Six Sigma adherent a "geek". "Idiot" would be a far better description. Unfortunately most of them will be lost after the first paragraph of Don's fantastic articles and we can be sure that the Six Sigma rubbish will not die.
The only change to the article should be added to "During the first half of the 20th century," "and first part of the 21st century owning to thousands of people fiddling with Minitab doing things they don't understand".
Geeks vs. Idiots
I was trying to be nice. Geeks usually LIKE being called geeks, but nobody likes to be called an idiot.
sjm ;-)
Clarity Even for "Six Sigma Geeks"
I am a Six Sigma geek, and Dr. Wheeler's columns are both understandable and always welcome. The only way to combat misinformation is by clearly repeating these sorts of explanations.
Add new comment