Mon, 06/04/2018 - 12:03
Social Sharing block
Body
Some properties of a probability model are hard to describe in practical terms. The explanation for this rests upon the fact that most probability models will have both visible and invisible portions. Understanding how to work with these two portions can help you to avoid becoming a victim of those who, unknowingly and unintentionally, are selling statistical snake oil.
Visible and invisible distributions
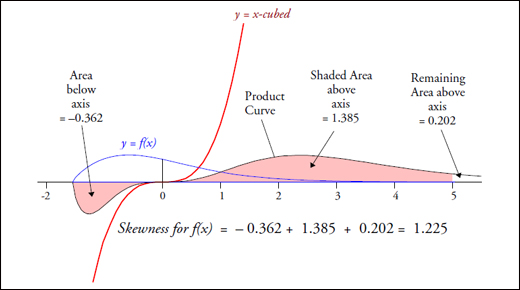
When a continuous probability model has an infinite tail or tails, that probability model can be divided into a visible portion and an invisible portion. To illustrate this I will use the probability density function for a standardized Burr distribution shown in figure 1.

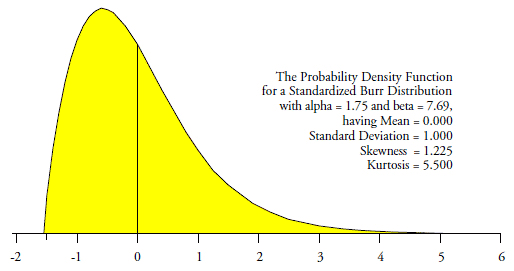
Figure 1: A standardized burr distribution
…
Want to continue?
Log in or create a FREE account.
By logging in you agree to receive communication from Quality Digest.
Privacy Policy.
Add new comment