Social Sharing block
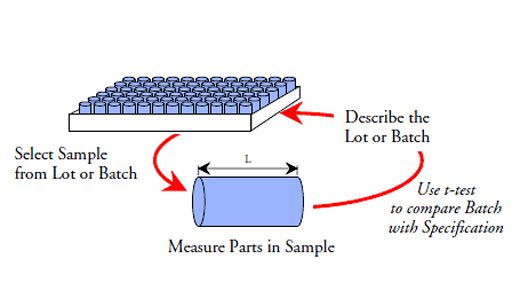
The ultimate purpose for collecting data is to take action. In some cases the action taken will depend upon a description of what is at hand. In others the action taken will depend upon a prediction of what will be. The use of data in support of these two types of action will require different types of analyses. These differences and their consequences are the topic of this article.
|
ADVERTISEMENT |
Descriptions of what is at hand
When the action to be taken will only affect the current situation, the lot of material on hand, or the product already made, then the problem of data analysis is essentially the problem of using measurements for description. The interest centers in what is, not how it got that way, or what it ought to be, or what it might have been. This is what W. Edwards Deming called an enumerative study.
…
Add new comment