Social Sharing block
One computation that modern software offers to unsuspecting users is the statistical tolerance interval. Since this sounds very much like limits for individual values, some have been tempted to use them on process behavior charts in place of the traditional three-sigma limits for individual values. To discover what tolerance intervals do, and do not do, read on.
|
ADVERTISEMENT |
Confidence intervals and tolerance intervals
Last month we considered the theoretical and practical aspects of finding a confidence interval for the mean. On the theoretical plane this involved finding the formula for a random interval that would bracket the mean value with some specified probability. In figure 1 this probability which is shown as 90% is the value commonly known as the "confidence level" for the interval estimate.
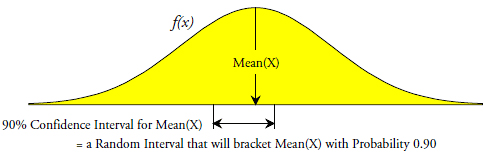
Figure 1: A 90% confidence interval for the mean
…
Add new comment