Social Sharing block
To summarize my last three articles, most improvement approaches come out of the same theory and are based on the assumption that everything is a process.
|
ADVERTISEMENT |
The universal process flowchart in Figure 1 sums it up beautifully. The boxes at the top are how executives think the process works. The frontline’s frustrating reality is charted underneath and is how it really works, which is why it needs improvement.
Figure 1: Universal process flowchart
In my last article, “Finding the Unnecessary and Everyday Variation,” I challenged you to give serious consideration to “the current everyday use of data” as a process, one that needs improvement. So let’s apply a tool common to all approaches—a high-level flowchart (shown in figure 2).
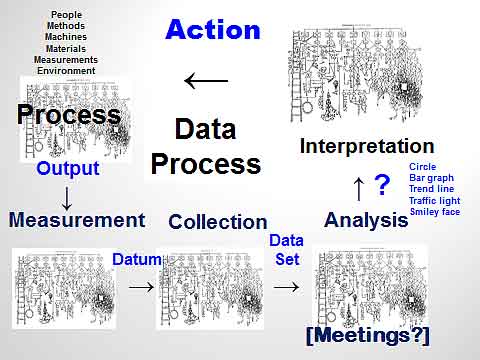
Figure 2: A high-level flowchart
…
Add new comment