
Cristiano Ronaldo (L), Lionel Messi (R)
Thu, 06/28/2018 - 12:03
Social Sharing block
Body
I recently got hold of the set of data shown in figure 1. What can be done to analyze and make sense of these 65 data values is the theme of this article. Read on to see what is exceptional about these data, not only statistically speaking.
|
ADVERTISEMENT |
|
|
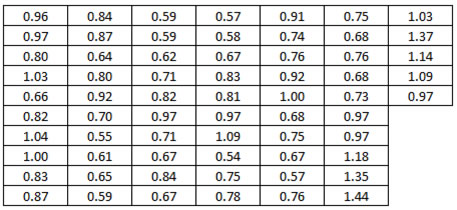
A good start?
While I was attending a training class several years ago, a recommended starting point in an analysis was to use the “Graphical Summary” in the statistical software, which is in the options for “Basic Statistics.” The default output for figure 1’s data set is shown in figure 2.
|
|
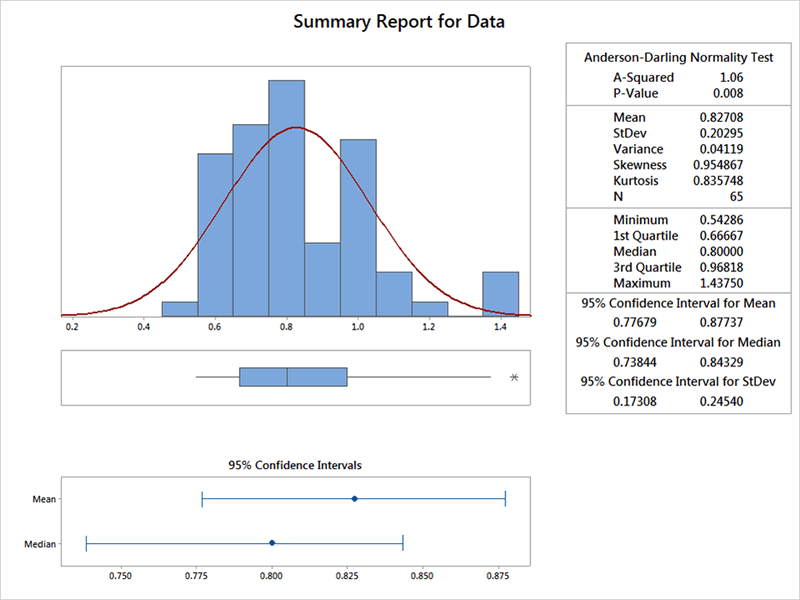
…
Want to continue?
Log in or create a FREE account.
By logging in you agree to receive communication from Quality Digest.
Privacy Policy.
Add new comment