Social Sharing block
Measurement error is generally considered to be a bad thing, and yet there is very little written about how measurement error affects the way we use our measurements.
This column will consider these effects for four different uses of data. But first we need to describe how to characterize measurement error in both an absolute and a relative manner.
The probable error
If we repeatedly measured the same thing thousands of times using the same measurement system, and if our measurements had very small increments, we would end up with a histogram of measurements like figure 1. Given such a collection of measurements, the intuitive estimate for the value of the thing being measured is the average of all of the measurements. But what does the dispersion of the histogram in figure 1 represent?
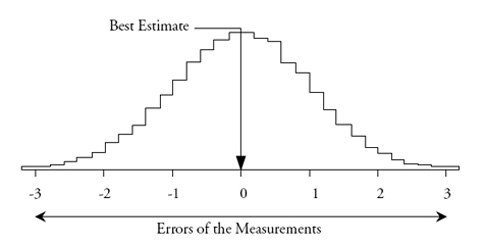
Figure 1: Repeated measurements of the same thing
…
Add new comment