Social Sharing block
Suppose you had 16 months of data on an important process (as plotted on the run chart seen in figure 1). For improvement purposes, an intervention was made after the sixth observation to lower this key process indicator. This intervention is equivalent to creating a special cause for a desired effect.
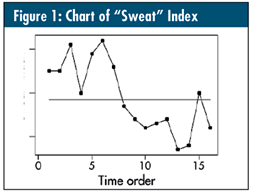
There is no trend as defined statistically (despite the trend downward of length five from observations 5 to 9; with 16 data points, one would need length six, or five successive decreases). Neither is there any run of length eight either all above or below the median. So, would you want to conclude that the intervention had no effect? I doubt it!
Think of the median as a reference, and consider each data point as a 50-50 coin flip (heads = above the median; tails = below the median). The question is: Would you expect to flip a coin 16 times and obtain the specific pattern of seven heads (run of length seven above the median), immediately followed by seven tails (run of length seven below the median), then a head (run of length one above the median) and, finally, a tail (run of length one below the median)? Intuition would seem to say, “No.” Is there a statistical way to prove it?
…
Comments
Other Methods of Detecting This Non-Randomness?
Wanting to understand this test better, and being the sort of person who prefers automatic solutions to manual ones, I am wondering if there are other ways of detecting this non-randomness (i.e. already implemented in software that I have available). Would any other tools provide the same test? It seems to me that an EWMA or CUSUM chart, with the right parameters, would detect number of runs below the lower limit, because the runs would be long, but on the high end?
I developed a table and regression for Num of runs
UL = Round( (3.376 + 0.5604 Num),0) excel or minitab
LL = Round( (- 2.409 + 0.4398 Num),0) excel or minitab
Num LL UL
2
0
4
3
0
5
4
0
6
5
0
6
6
0
7
7
1
7
8
1
8
9
2
8
10
3
8
11
3
9
12
3
10
13
4
10
14
4
11
15
4
12
16
5
12
17
5
13
18
6
13
19
6
14
20
6
15
21
7
15
22
7
16
23
8
16
24
8
17
25
9
17
26
9
18
27
9
19
28
10
19
29
10
20
30
11
20
31
11
21
32
11
22
33
11
22
34
12
23
35
13
23
36
13
24
37
14
24
38
14
25
39
15
25
40
15
26
41
16
26
42
16
27
43
17
27
44
17
28
45
17
29
46
18
29
47
18
30
48
19
30
49
19
31
50
19
32
51
20
32
52
20
33
53
21
33
54
21
34
55
22
34
56
22
35
57
23
35
58
23
36
59
24
36
60
24
37
61
24
38
62
25
38
63
25
39
64
26
39
65
26
40
66
27
40
67
27
41
68
27
41
69
28
42
70
28
43
71
29
43
72
29
44
73
30
44
74
30
45
75
31
45
76
31
46
77
31
47
78
32
47
79
32
48
80
33
48
81
33
49
82
34
49
83
34
50
84
35
50
85
35
51
86
35
52
87
36
52
88
36
53
89
37
53
90
37
54
91
38
54
92
38
55
93
38
55
94
39
56
95
39
57
96
40
57
97
40
58
98
41
58
99
41
59
100
42
59
101
42
60
102
42
61
103
43
61
104
43
62
105
44
62
106
44
63
107
45
63
108
45
64
109
46
64
110
46
65
111
46
66
112
47
66
113
47
67
114
48
67
115
48
68
116
49
68
117
49
69
118
49
70
119
50
70
120
51
70
121
50
71
122
51
72
123
51
72
124
52
73
125
52
73
126
53
74
127
53
75
128
53
75
129
54
76
130
54
76
131
55
77
132
55
77
133
56
78
134
56
78
135
57
79
136
57
80
137
57
80
138
58
81
139
58
81
140
59
82
141
59
82
142
60
83
143
60
84
144
60
84
145
61
85
146
61
85
147
62
86
148
62
86
149
63
87
150
63
87
151
64
88
152
64
89
153
64
89
154
65
90
155
65
90
156
66
91
157
66
91
158
67
92
159
67
92
160
68
93
161
68
94
162
68
94
163
69
95
164
69
95
165
70
96
166
70
96
167
71
97
168
71
98
169
71
98
170
72
99
171
72
99
172
73
100
173
73
100
174
74
101
175
74
101
176
75
102
177
75
103
178
75
103
179
76
104
180
76
104
181
77
105
182
77
105
183
78
106
184
78
106
185
79
107
186
79
108
187
79
108
188
80
109
189
80
109
190
81
110
191
81
110
192
82
111
193
82
112
194
82
112
195
83
113
196
83
113
197
84
114
198
84
114
199
85
115
200
85
115
Add new comment