|
|
|||||||||||||||||||||
 |
 |
||||||||||||||||||||
 |
|||||||||||||||||||||
How Much Data Do I Need? The relationship between degrees of freedom and the coefficient of variation is the key to answering the question of how much data you need. by Donald J. Wheeler |
|||||
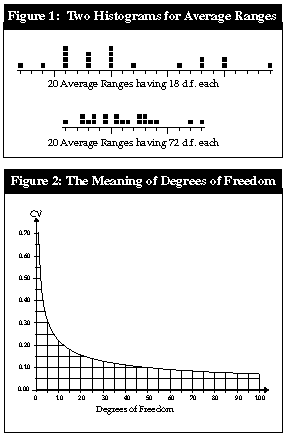
How much data do I need to use when I compute limits?" Statisticians are asked this question more than any other question. This column will help you learn how to answer this question for yourself. Implicit in this question is an intuitive understanding that, as more data are used in any computation, the results of that computation become more reliable. But just how much more reliable? When, as more data become available, is it worthwhile to recompute limits? When is it not worthwhile? To answer these questions, we must quantify the two concepts implicit in the intuitive understanding: The amount of data used in the computation will be quantified by something called "degrees of freedom," and the amount of uncertainty in the results will be quantified by the "coefficient of variation." The relationship between degrees of freedom and the coefficient of variation is the key to answering the question of how much data you need. The terminology "degrees of freedom" cannot be explained without using higher mathematics, so the reader is advised to simply use it as a label that quantifies the amount of data utilized by a given computation. The effective degrees of freedom for a set of control limits will depend on the amount of data used and the computational approach used. For average and range charts (X-bar and R charts), where the control limits are based upon the average range for k subgroups of size n, the degrees of freedom for the limits will be: d.f. ~ 0.9k(n1). For example, in April's column, limits were computed using k = 6 subgroups of size n = 4. Those limits could be said to possess: 0.9 (6) (3) = 16.2 degrees of freedom. For average and standard deviation charts (X-bar and s charts), where the control limits are based on the average standard deviation for k subgroups of size n, the degrees of freedom for the limits will be: d.f. ~ k(n1) 0.2(k1). In my April column, if I had used the average standard deviation to obtain limits, I would have had: (6) (3) 0.2 (5) = 17 degrees of freedom. As will be shown below, the difference between 16 d.f. and 17 d.f. is of no practical importance. For XmR charts, with k subgroups of size n = 1, and limits based on the average moving range, the degrees of freedom for the limits will be: d.f. ~ 0.62 (k1). In my March column, I computed limits for an XmR chart using 20 data. Those limits possessed: 0.62 (19) = 11.8 degrees of freedom. The better SPC textbooks give tables of degrees of freedom for these and other computational approaches. However, notice that the formulas are all functions of n and k, the amount of data available. Thus, the question of "How much data do I need?" is really a question of "How many degrees of freedom do I need?" And to answer this, we need to quantify the uncertainty of our results, which we shall do using the coefficient of variation. Control limits are statistics. Thus, even when working with a predictable process, different data sets will yield different sets of control limits. The differences in these limits will tend to be small, but they will still differ. We can see this variation in limits by looking at the variation in the average ranges. For example, consider repeatedly collecting data from a predictable process and computing limits. If we use k = 5 subgroups of size n = 5, we will have 18 d.f. for the average range. Twenty such average ranges are shown in the top histogram of Figure 1. |
|||||